Gemma 4 Exceeds Expectations
In a previous post, I tested a bunch of models on the problem of finding bugs in the wild originally reported by Mythos. This proved pretty challenging for even frontier models, with the best models finding four of nine (a couple also got one or two partial credits, where they found the bug but misunderstood it according to the Opus 4.8 judge).
One of the surprisingly effective models was Gemma 4. The MoE version found 4/9 (though only got credit for 3, because it only found the fourth during extra runs while trying to fix llama.cpp issues, and giving it a bunch of attempts seemed unfair to the other models that only got one attempt for each case). At first, it looked like the dense model did worse than the MoE, but on a deeper dive into the data, I saw that Opus had declared two of its findings “wrong bug”, even though they were exactly the right lines of code and when I read the bug description Gemma 4 gave, I think it’s pretty reasonable to say it found the bug well enough to where a developer could understand the problem and fix it. So…Gemma 4 is a top performer. Beating the already surprisingly high performance of Qwen 3.6 27b. This was the point where I decided to add the “partial” column to the baseline benchmark, which revealed Qwen 3.7 Max, Gemini 3.1 Pro, Owl Alpha, Kimi 2.7-Code, and Laguna m.1 were all at least a little better than initially indicated. I’m still undecided on how best to reflect those partial credits in the ranking. Sometimes I agree with Opus that the model misunderstood, and sometimes I don’t. But, if the model detects a smell in the exact right area of the code, that’s worth something.
I wanted to probe those Gemma 4 results a bit more, as I did with Qwen, where I tested three hypothesis at once: Can a different prompt change the outcome (probably no), can repeated attempts improve the outcome (a qualified yes), and does quantization matter (mostly no, at least down to 4-bit).
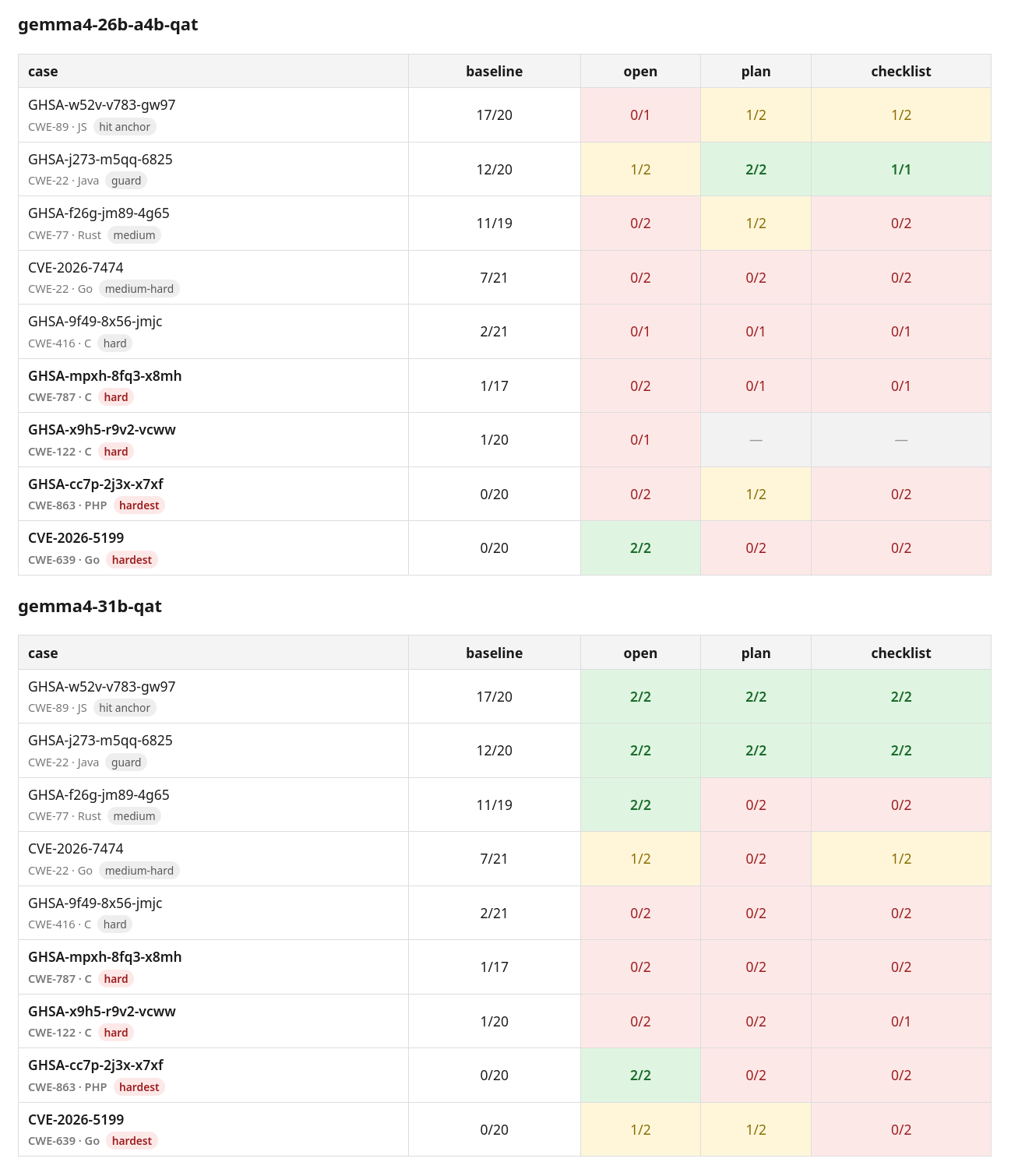
So, I ran a similar test with the 31b and the 26b-a4b MoE versions. Since I’d already found that quantization doesn’t seem to hurt in a measurable way on this task, and since I know the QAT version of Gemma 4 is very good, seemingly indistinguishable from the full-fat version, I decided to only test the 4-bit QAT version this time. We’re still testing two hypothesis (which don’t interfere with each other): Can the prompt change the outcome? and Can repeated attempts improve outcomes? The result this time was, “maybe for the worse?” and “very yes”. Giving Gemma 4 31b multiple attempts allows it to find six (6!) of the nine bugs, including extremely hard to find bugs that only one or no other model found in the original benchmark. That’s a shocking outcome for a tiny open weight model that is comfortably self-hostable in 64GB.
This was the same basic test as before: Nine bugs originally found by Mythos, the same bugs all of the models in the big benchmark have looked at. The model is given the file where the vulnerability exists, and read/grep/ls tools for exploring the whole repository. As in previous benchmarks, it is not given any hints about the type of problem, it’s merely asked to report any security bugs it finds.
This benchmark run included two runs for each model with each of three different prompts, “open”, “plan”, and “checklist”.
- open : the plain neutral file-audit prompt (control / variance floor). Basically, just “report security bugs in this file” as in the baseline benchmark.
- plan : prepend a threat-modelling scaffold (enumerate inputs, resource lifetimes, authz) and reason before answering.
- checklist : fold the language’s applicable common weakness classes into ONE pass as a breadth checklist
As in the Qwen benchmark, the simplest “open” prompt seems to be the winner, but also as with Qwen, there’s enough noise, especially in the MoE results, to where I’m not entirely sure. I think a pattern is emerging that micromanaging the model by prompting it very specifically with a bunch of things to think about is probably suboptimal. At the very least a longer, more complicated, prompt may be wasting time and effort and tokens. More data is still needed.
Once again the MoE got “lost” pretty often in a generative loop where it would repeat itself in the reasoning step until the harness timed out. If I do any more tests on the MoE (and I may not, given its poor performance here), I’ll run it with frequency_penalty and repeat_penalty raised a little bit, to hopefully kick it out of the forever loop, which prevented it from answering at all on a few attempts (where you see either 0/1, 1/1, or — in the chart, the model timed out at least once due to a reasoning loop). That mostly happened on bugs that it probably wouldn’t have found, anyway, as the dense model is consistently better at this task and it didn’t find them, so I didn’t try to fill in those gaps. I’ll do more testing of Gemma 4 in the future, though, as it’s easy to self-host at a reasonable speed, so it’s close to free to experiment with, and it’s shockingly good at this job, given its size, so it’s an interesting area for research.
Results
Conclusions
Pretty impressive results for a tiny model that fits on a quite normalish developer machine. The dense version of Gemma 4 runs comfortably on my desktop machine with dual 32GB Radeon Pro V620 GPUs (five year old data center GPUs) or on the Strix Halo with 128GB, albeit a bit more slowly. It would also be fine on any recent Mac with 64GB of unified memory, as long as you don’t go overboard with context. This test makes Gemma 4 31b the best model I’ve tested, finding six of nine bugs. Obviously, when I run the same replication runs on the other models, they will very likely also find more bugs. But, the Qwen results made me think there was a hard boundary on smaller models finding most of these bugs. Which this benchmark refutes.
Oh, and of course, now we see the MoE is really prone to hallucinated bugs, making it unfit for this purpose. It’s fun to chat with because it’s very fast, even on modest hardware, but when precision and real deep thinky thoughts are needed, there’s a lower bound and the MoE is well under it. I wouldn’t try to use it for any serious security work, even though it did find a pretty good number of the bugs, more than some much larger models.
The dense model also had a few false positives, but probably not enough to be disqualifying. False positives are particularly bad in a security research tool, as any bug report needs to be investigated somehow. Either by other models or by a human or both. So, a bunch of good bug reports get a lot less valuable when they’re mixed with a bunch of false positives. Gemma 4 is majority real. We’ll see how other models stack up when they are given multiple chances per bug.
My next steps with Gemma are to run more tests with more tools available, and perhaps a “bughunt loop” where the model gets a checklist of several tactics to try and the necessary tools to try each of those tactics. That will be a larger time investment, though, so it might be a little while before I get to it. Future experiments with Gemma 4 will probably focus on the 31b dense model and skip testing on the MoE, since it’s pretty clear it’s not up to the task. Here’s hoping the Google folks have a bigger MoE up their sleeves…a 70b, or even 120b, would be really nice for self-hosters with 128GB systems.