Qwen 3.6 Quantization Degradation
Qwen 3.6 punches well above its weight in hunting hard security bugs, as I noted in a previous post. It’s obviously not a frontier model, and doesn’t quite perform like one, but it consistently finds a couple of security bugs that many larger models miss.
I usually use the dense model, because it feels smarter than the MoE model, even though the MoE model is much faster. And, I usually use the 8-bit quantization, because the model necessarily gets less effective with less data. But, I also know the noticeable intelligence drop comes somewhere below 6 bits. So, I compared several quantized versions of both the dense and MoE model on six of the Mythos-found bugs that I used for the previous benchmark, with one “easy” bug (that many models found in the original benchmark, and Qwen always finds, labeled “hit anchor”), one bug that Qwen usually finds and most small models do not find (labeled “guard”, as it indicates whether quantization or MoE makes a notable difference), one “edge” bug (that some models found, some didn’t, labeled “medium”), and three “hard” bugs (bugs that only one frontier model or no model found).
The result is that the degradation of both models when reducing from 16-bit all the way down to 4-bit quantization was small enough to not make a statistical difference in detection on this particular data set. The dense model outperforms the MoE, with the MoE consistently missing the “medium” difficulty Rust bug in GHSA-f26g-jm89-4g65, for every quantization except the BF16 version, where it found it once and missed it once with the checklist prompt. All other attempts by the MoE to crack this very hard bug failed.
Caveats
This is a very limited benchmark with only six vulnerabilities. And, it is only two runs of each prompt on each model at each quantization. But, results are pretty consistent.
Results
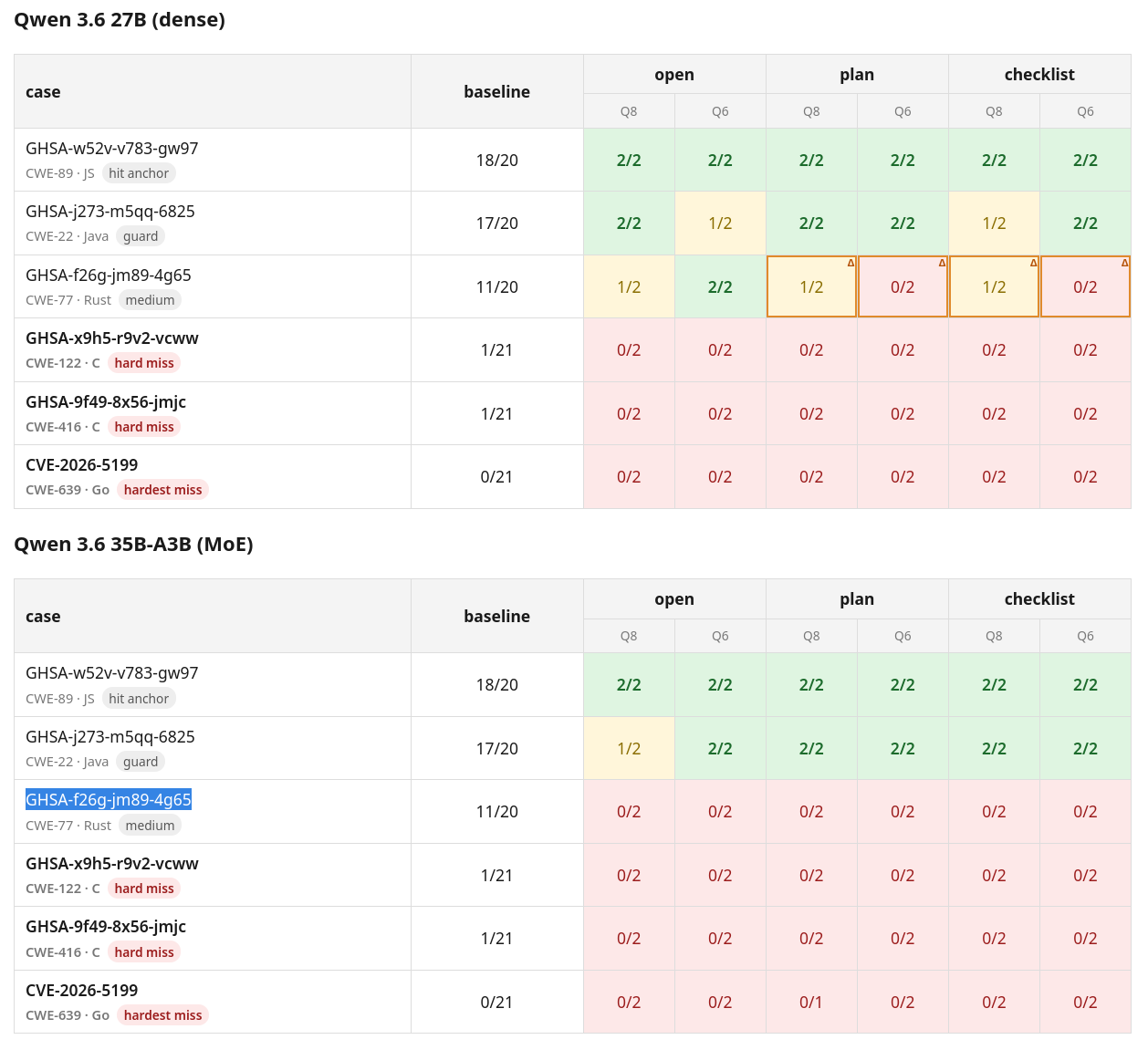
Test Parameters
This benchmark run included two runs for each model with each of three different prompts, “open”, “plan”, and “checklist”.
open: the plain neutral file-audit prompt (control / variance floor).plan: prepend a threat-modelling scaffold (enumerate inputs, resource lifetimes, authz) and reason before answering.checklist: fold the language’s applicable weakness classes into ONE pass as a breadth checklist
Open seems to perform best, though it’s a small enough difference to where it could be statistical noise. More tests are warranted. And, realistically, the most effective process probably involves giving the model access to stuff like a fuzzer, a debugger, and a compiler or whatever static analysis tools are available. And, frankly, a lot of vulnerabilities in the wild are quite low-hanging fruit, and would be found with static analysis, if only static analysis were in use.