Shell Games
I recently added Ornith 1.0 to the Will It Mythos benchmark. Ornith is a Qwen or Gemma 4 post-train (the one I tested is based on Qwen 3.5 35B MoE, I believe) that teaches the model to build its own harness for solving problems. They call it “self-improving”, but I’m skeptical of that claim, for a few reasons. But, it’s also an interesting idea.
To be clear, LLMs don’t improve with use. They can’t improve. They don’t have what we think of as “memory”. They have context, a relatively small active data set that is processed on each “turn” of the conversation with the model. The model is adding to the conversation with the most probable next words, and all the words up to that point contribute to what it says next. When Claude or other agent says it’s saving a memory, it means it is putting a piece of data into a database that may be retrieved and injected in the model’s context in the future, so that piece of old data becomes part of the ongoing conversation that the model considers when it formulates the following words.
But, what Ornith does is build task scaffolds that act as levers to make the model better able to solve problems. From the blog, “Ornith-1.0 treats the scaffold as a learnable object that co-evolves with the policy”, whatever that means. (Models currently can’t co-evolve without more training, a slow and expensive process.)
Anyway, the poor performance of Ornith 1.0 35B on the benchmark, compared to other models of similar size (Gemma 4, in particular), led me to consider ways to let it shine. Since it’s advertised as a tool (“scaffold”) builder, rather than merely a tool user, I figured I’d give it a full shell and Python environment. Let it build.
And, since I was running the test, anyway, I might as well see if giving the other models more tools helped them perform better. I’ve done other benchmarks like this, with mixed (mostly negative) results, such as including semgrep or tree-sitter in the avilable tools. Mostly, more tools confused smaller models and was a wash for bigger models, except MiMo which seemingly always gets worse the more tools you give it (an excellent baseline performance without tools, though). But, those are specialized tools with limited information in the training data. Python and bash are copious in the training data, maybe more prevalent than anything else. Even very small models are comfortable with Python and bash. And, so far, the theory seems to bear out.
When given a shell and Python, Ornith doubled its findings, and without a spike in false positives. Still not the best small model for this task (that’s Gemma 4 31B), but it does indicate that tool-building does elevate its performance. And, the expanded palette of tools helped DeepSeek crack a hard bug it had never cracked before, at least on one run, raising its total “bugs found” count to five of nine. That’s pretty interesting. It’s evidence that multiple passes of a very cheap model like DeepSeek V4 Pro, with a rich set of tools, can find bugs that only the most expensive models (Mythos and GPT 5.5 Pro, in this specific case) found previously.
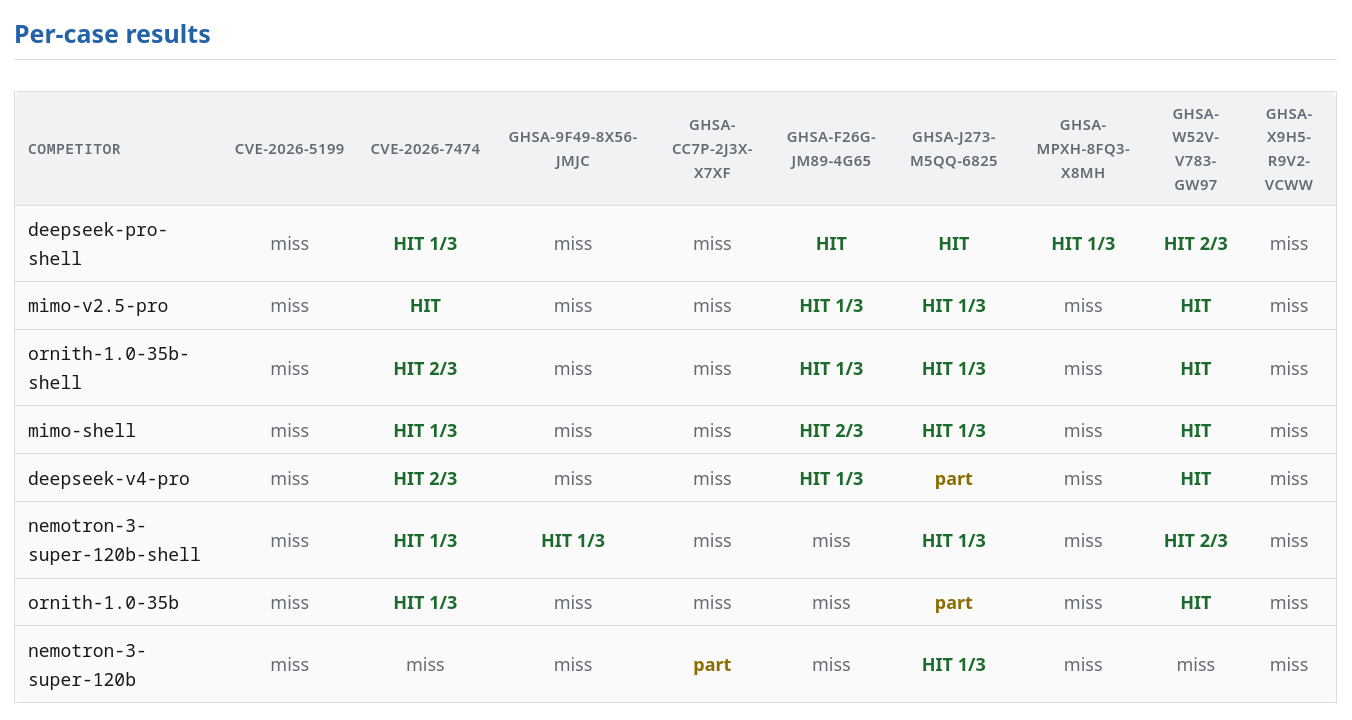
I did three control rounds (same as the baseline benchmark in Will It Mythos, with read/grep/ls tools) and three rounds with the original tools as well as bash and a pretty complete Python environment (but no pip, since network is disabled to prevent cheating). The latter group has shell appended to their name in the results.
Probably the most interesting bit of the benchmark is the “Per-case results”. This gives evidence of a few things:
- We’re probably not at the upper bound on how many of these bugs these models can find. Giving them multiple attempts continues to increase their hits, and the several 1/3 results means there’s probably still room to grow. More research needed, but it’s already clear a harness that runs multiple attempts, de-dupes, and then judges for false positives, is the right way to make any model perform better.
- MiMo got lucky on the baseline. It found the same number of bugs in this run, but only by running it three times. MiMo would find somewhere between two and four bugs, it just happened to find four on that first run, making it look better than it turns out to be.
- DeepSeek is clearly better than MiMo after more testing, and it is also less confused by more tools. In previous tool expansion experiments, DeepSeek performed slightly better with
tree-sitterin the mix and no worse withsemgrepin the mix, while MiMo performed worse in all cases. - Ornith 1.0 performed remarkably better with a full shell and Python, climbing to third place in total bugs found, directly competitive with MiMo v2.5 Pro (without a shell, again giving MiMo too many things to think about confuses it).
- Nemotron also performs much better with a shell and Python, doubling its findings as well, rising into the “found four bugs” group. MiMo is the outlier in being confused by more tools.
- I now wish I’d included Gemma 4 in this group, as it’s a remarkably good performer at this task (when given multiple passes, it finds 6/9 bugs, with only the read/grep/ls tools). I’ll be running a Gemma 4 test with shell soon.
- It’s time to rewrite Nelson based on the new data. Brute force and repetition are the keys to finding security bugs. A full shell and Python probably helps. So, the next version of Nelson will remove the focused mode, as it was actually the repetition that was finding more bugs, not the “focus on a specific CWE”. Turns out just having the agent look at it several times is enough to improve its result, moreso than telling it to find specific problems. Multiple models is also probably a good idea, but still not necessarily the most expensive models, though the most expensive models are consistently good performers.
Results